
Progressive Face Super-Resolution via Attention to Facial Landmark arxiv.org is a machine learning model trained to reconstruct face images from tiny 16×16 pixel input images, scaling them up to 128×128 with nearly photo-realistic results. Here’s an example:


A detail not mentioned in the official paper, pretty high percentage of Harry-Potter-style scars…🤨
This is a best case scenario for this model. While I didn’t cherry pick these samples, these faces are cropped to the right size, they are roughly aligned, and they were resized to 16×16 pixel input images with the exact same code that was used to train and test the model. This is what this model was built for.
What about what it wasn’t built for?
Twitter conveniently created a set of emojis that are exactly 16×16 pixels in size…
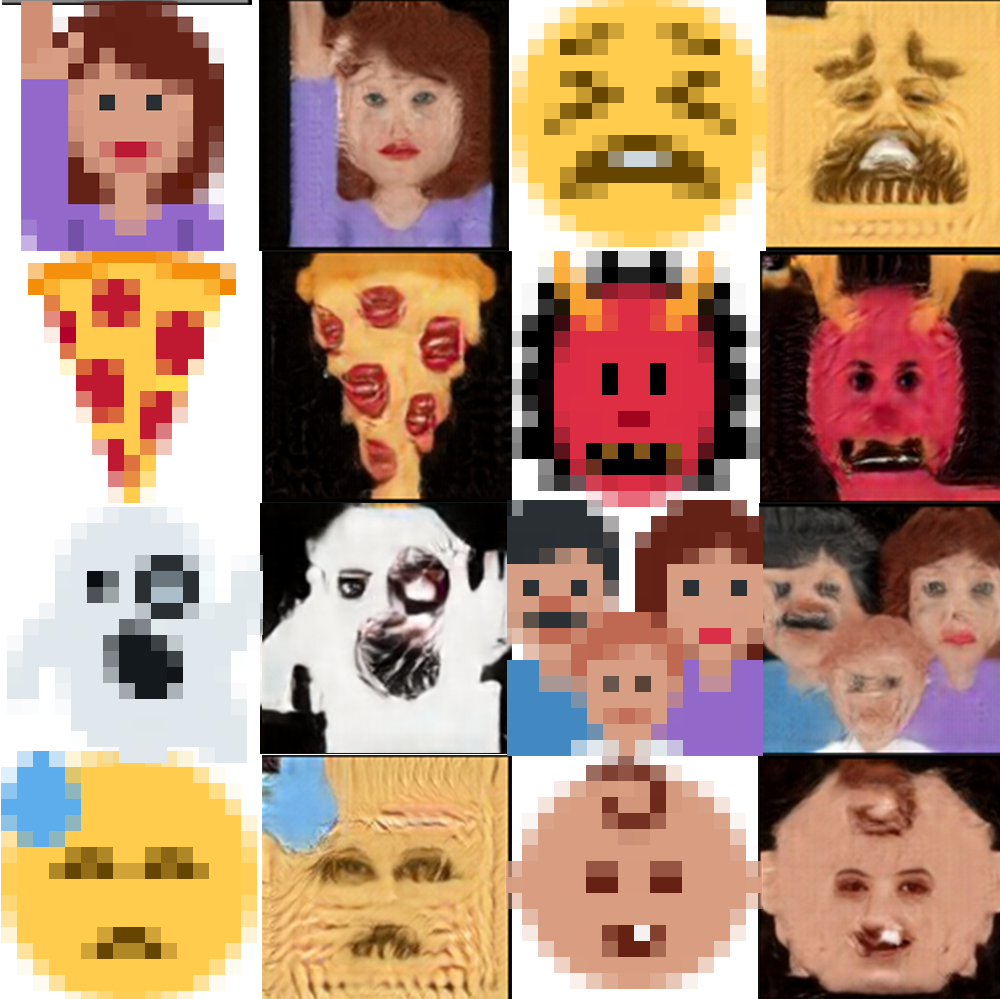
Now we’re getting somewhere! Because this model is trained specifically to look for facial landmarks it will take any excuse to draw eyes and nostrils on a pixel. And I’m pretty sure the pepperoni on that pizza is made out of human lips… 😶
These samples are cherry picked and many outputs were not very interesting. I also went to some lengths to encourage the model to make aggressive guesses about facial features. For example, while the twitter image was already exactly 16×16 pixels, I had better results generally if I first resized it from 16×16 input up to 128×128 via traditional resizing, and then back down to 16×16. This adds a lot of blur which seems to gives the model more room to creatively interpret things. I also iteratively sent the predicted images back into the model as inputs — as many as 10 times — and many of these are from later iterations. It was pretty common to see human eyes in only 3 out of 10 iterations, for example. Here’s some more:



Love this green guy. He never really got human features except for the one eyelid, but the I love the artifact style here.

The distortions reminds me of this Gan Steerability paper, when you zoom in or out of a StyleGAN face model.
Here’s the Face Super-Resolution model zooming:


What About Twitch Emotes?

Twitch emotes are not available exactly in 16×16, and some of them have high resolution versions while other do not. I tried all sorts so for some of the following the input was already high resolution, but before it goes into the model it was resized down to 16×16. I left these in because there was often an amusing contrast against the real high resolution emote. More:






And Finally, Video Game Sprites.

Going Further
I think there’s a lot more that could be done to encourage the model to be creative in applying human features — I just tried a few tweaks to the pipeline and iterating, hardly anything. And using other models the possibilities are endless. StyleGAN encoding immediately come to mind:


A quick test of Selfie2Anime.com:




Update 1: More Minecraft
I was asked to try more Minecraft textures, which are 16×16 pixels naturally. The vast majority didn’t really work but a few of them… 😶

Here’s the full set
The facial features are generally very subtle, which is honestly a lot more creepy than the overt ones. Imagine playing the game and just having a sensation of seeing a face, but you can’t quite place it…




Update 2: I can’t stop trying things
Update 3: Video
Update 4: Some Different Cases

Try It Yourself
A quick Colab Version of this project I slapped together.
Such an adorable hairy little Goomba!

I am not sure since i am a begginer at this, but the last gif seen to have the tensorflow bug on resize?
https://hackernoon.com/how-tensorflows-tf-image-resize-stole-60-days-of-my-life-aba5eb093f35
do pedobear!